Git Lucky : jouer en harmonie grâce à Conventional Commits
Selon la manière dont sont rédigés les messages de commits d’une pull request, une revue de code peut s’apparenter, dans le meilleur des cas, à la lecture d’un bon roman à suspense, et dans le pire, au travail archéologique minutieux nécessaire pour comprendre les textes de loi d’une civilisation extraterrestre disparue depuis cinq millénaires.

Fort heureusement, la spécification Conventional Commits peut nous aider à écrire de meilleurs messages de commit, faciliter la vie de nos collègues ou de cette personne inconnue qui maintient un projet open source auquel nous avons envie de contribuer, et faire de notre pull request une partition sans fausses notes qui permettra au groupe de jouer en harmonie.

Documenter les changements
La revue de code par les pairs est une étape essentielle pour garantir la qualité du code d’un projet. Au-delà de s’assurer que le code fait bien ce qu’on attend de lui, c’est aussi l’occasion de vérifier qu’il respecte bien les standards d’une équipe ou d’une organisation, qu’il est lisible et qu’il est bien testé. Le code que l’on s’apprête à intégrer au projet sera peut-être encore exécuté des mois, voire des années plus tard, et une bonne revue augmente fortement les chances qu’il soit encore fonctionnel, facile à maintenir et compréhensible à ce moment-là.
Je crée des pull requests dont je pense qu’elles sont bien plus faciles à relire depuis que je me dis qu’un commit est comme un commentaire : il sert à documenter.
Mais là où le commentaire va expliciter une portion de code, le commit et son message devraient expliciter pour quelle raison cette portion de code a changé, et fournir le contexte nécessaire à cette compréhension.
Par exemple, en regardant le commit ci-dessous, êtes-vous capable de dire pourquoi ces lignes ont été supprimées ? La méthode a-t-elle été déplacée dans une autre classe ? A-t-elle été renommée et déplacée dans la même classe ? Ou peut-être que le code n’était utilisé qu’à un seul endroit et qu’on a jugé qu’il n’était pas nécessaire d’avoir une méthode dédiée ? Le message de commit ne vous apporte pas beaucoup plus d’informations, n’est-ce pas ?
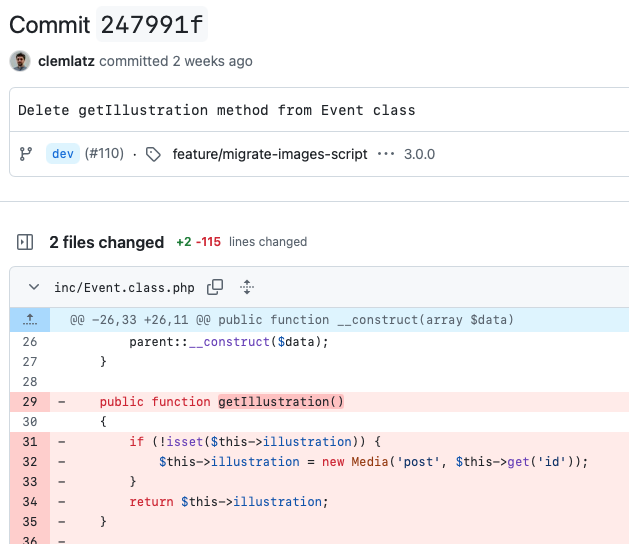
En réalité, sur ce commit, le véritable message était le suivant :
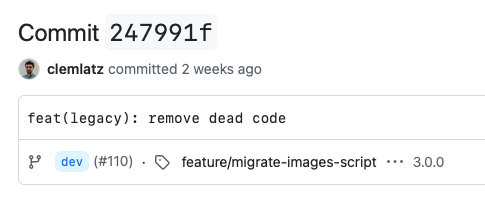
Oublions pour l’instant le préfixe feat(legacy) sur lequel nous reviendrons, et notons que le message lui-même est beaucoup plus simple. On pourrait penser qu’il en dit moins, mais en réalité, il donne une information plus pertinente. Plutôt que d’indiquer quelle modification a été faite — le quoi —, il explicite pour quelle raison elle a été faite — le pourquoi. Le quoi devrait être évident quand on regarde le diff (l'avant/après du commit), et si ce n’est pas le cas, c’est sans doute que le commit est trop gros et embarque trop de modifications.
Et ça tombe bien : la spécification Conventional Commits, en nous incitant à nous intéresser au pourquoi du commit plutôt qu’au quoi, nous pousse non seulement à rédiger de meilleurs messages, mais aussi découper notre pull request au plus fin, avec les commits les plus petits et les plus porteurs de sens possible.
Qu’est-ce qu’un bon message de commit ?
Lorsqu’on aborde un commit, son message est bien souvent la première chose que l’on lit, avant de voir le code modifié. Il va donc, idéalement, influencer notre manière de lire ces changements. Notamment, il devrait nous préparer à attendre un certain nombre de choses selon le type de modification.
Par exemple, un commit corrigeant un bug devrait être accompagné d’un test visant à détecter une future régression. Un commit proposant une refactorisation interne à une classe pour rendre le code plus lisible ne devrait pas nécessiter de modifier un test haut niveau comme un test end-to-end. Sinon c’est peut-être le signe qu’il introduit un breaking change. Si un commit dont le but est d’améliorer un test unitaire modifie aussi la méthode testée, aïe aïe aïe ! Nous avons peut-être une implémentation dépendante des tests — ce qui est une très mauvaise pratique !
Conventional Commits à la rescousse

Comment Conventional Commits peut-il nous aider ? Et de quoi s’agit-il exactement ? D’après le site officiel, c’est :
Une spécification qui permet une signification lisible pour l'humain et pour la machine dans les messages des commits.
On mentionne la machine, car Conventional Commits est aussi utile pour automatiser certaines tâches dans le cadre d’une intégration continue. Mais aujourd’hui, ce sont bien les humains — et la manière dont ils collaborent — qui nous intéressent. Pour la même raison, je ne retiendrai que ces deux raisons d’utiliser la spécification, énoncées sur le site officiel :
- Communiquer la nature des changements aux membres de l’équipe, au public et aux autres parties prenantes.
- Faciliter la contribution des personnes à vos projets en leur permettant d’explorer un historique de commits plus structuré.
Il s’agit donc bien de faciliter la vie aux collègues qui reliront votre code, que ce soit le lendemain pour une revue de code ou longtemps après pour les explorateurs et exploratrices de l’historique. Sachant que, dans le dernier cas, la personne perdue devant un bout de code écrit des mois plus tôt et devenu incompréhensible, c’est parfois celle qui a écrit de ce bout de code : vous.
Anatomie d’un message de commit
À quoi ressemble un message de commit respectant Conventional Commit ? Voici la structure à respecter, avec les éléments obligatoires entre <chevrons> et les éléments facultatifs entre [crochets] :
<type>[optional scope][optional !]: <description>
[optional body]
[optional footer(s)]L’en-tête
Il rassemble, sur une seule ligne, les informations essentielles du message de commit. Il est composé du type, de l'étendue (facultative) et de la description. Par exemple :
feat(api): add a /users/logout routeLe type (dans l’exemple feat)
II permet à la personne qui va relire le code de comprendre, au premier coup d’œil, l’objet du commit et ce qu’on peut s’attendre à y trouver. Un commit qui introduit une nouvelle fonctionnalité ne ressemblera probablement pas du tout à un autre qui améliore la documentation. On ne va pas s’attendre à des modifications aux mêmes endroits de la base de code et on ne va pas faire attention aux mêmes bonnes pratiques.
L'étendue (en anglais scope, dans l’exemple (api))
Elle permet de préciser la partie de la base de code affectée par le commit. Conventional Commits ne propose pas de liste de scopes prête à l’emploi. C’est à chaque équipe de les définir en fonction de son contexte. Cela peut être le nom d’un projet dans le cadre d’un « monorepo »1 ou un projet pour une équipe rompue au DDD 2.
Pour moi, une des grandes vertus de l'étendue est qu’elle oblige à découper finement les commits. Si vous ne savez pas quelle étendue choisir ou si vous avez envie d’en mettre plusieurs, c’est probablement le signe que le commit est trop gros.
L'étendue, facultative 3, s’entoure de parenthèses et se place entre le type et le symbole « : ».
La description (dans l’exemple add a /users/logout route)
Elle correspond à ce qu’on le retrouve dans un message de commit classique. Parfois, une convention peut s’appliquer à cette section (par exemple, commencer par un verbe à l’infinitif), mais Conventional Commits ne dit rien du contenu attendu d'un message. C’est mon opinion personnelle qu’un message qui se contente de décrire (dire quoi) est moins pertinent qu’un message qui lui, explicite la raison d’être du commit (dire pourquoi).
La description est séparée du type (et éventuellement de l'étendue entre parenthèses) par le symbole « : », suivi d’une espace.
Les éléments facultatifs
Corsons un peu les choses avec un commit qui nécessiterait plus de contexte et impliquerait d’utiliser l’ensemble des éléments facultatifs. Il aurait plutôt cette tête-là :
feat(api)!: remove redundant /users/deconnexion route
The removed route was redundant with the /users/logout route and
the french word was inconstant with our route naming standards.
BREAKING CHANGE: front-end applications must use the /users/logout route
instead of the /users/deconnexion route.Le point d’exclamation (« ! »)
Il se place avant le symbole « : » et permet d’indiquer qu’un commit introduit un breaking change. Selon Conventional Commits, il peut être associé à un n’importe quel commit ; pour ma part, introduire un breaking change avec une correction de bug ou une refactorisation est une très mauvaise pratique, et l’associer à un commit qui améliore la documentation n’a pas de sens. Seul un commit affectant une fonctionnalité (de type feat) devrait être accompagné d’un point d’exclamation, et son introduction devrait être réfléchie et documentée.
Le corps (en anglais body)
Il s’insère après une ligne vide et permet d’apporter un complément d’informations (sur le pourquoi) si la première ligne du message n’est pas autoportante. Celle-ci étant idéalement limitée à 72 caractères, le surplus étant masqué, par exemple sur GitHub. Cela peut être utile si l’on suppose que le lecteur aura besoin d’un contexte supplémentaire pour comprendre la raison de ce changement dans le code.
Le pied de page (en anglais footer)
Il s’insère lui aussi après une ligne vide et permet d’ajouter des métadonnées au message de commit, au format « git trailer » (qui ressemble aux en-têtes des emails de la RFC 822). Conventional Commits n’en propose qu’un seul exemple avec un pied de page BREAKING CHANGE:, qui permet, en plus du marqueur « ! », de préciser les actions à effectuer pour corriger un breaking change, instructions qui pourront par la suite ajoutées aux releases notes.
Bien sûr, rien n’empêche d’imaginer d'autres pieds de page selon les besoins du projet. « Mais attends », vous dites-vous peut-être, « qu’est-ce que c’est que c’est que cette convention où on peut faire un peu ce qu’on veut ? ».
Eh bien, précisément, Conventional Commits n’est pas une convention, mais une spécification. Peut-être le temps est-il venu, avant de nous intéresser aux types de commit, de nous intéresser à ce détail important et à ce qu’il signifie.
Mais au fait, pourquoi une spécification ?
Si l’on regarde la spécification Conventional Commits avec attention, on remarquera que seul deux types y sont réellement définis : feat et fix. Vous utilisez peut-être aussi refactor ou build en pensant que ces types relèvent de Conventional Commits. En réalité, vous utilisez probablement, et peut-être sans le savoir, la convention Angular ou celle, légèrement différente, de commitlint.
On présente souvent à tort, moi le premier, Conventional Commits comme une convention ou un standard, alors qu’il s’agit en réalité d’une spécification pour écrire une convention.
La différence est subtile, mais fondamentale : Conventional Commits n’est pas un standard universel, mais un outil que chaque projet ou équipe devrait s’approprier pour bâtir la convention qui lui convient.
Tout comme une bonne pratique n’est « bonne » que dans un contexte particulier, parce qu’elle résout ou prévient un problème précis, une convention devrait être décidée collectivement par les personnes qui vont avoir à l’appliquer. S’il est possible de s’inspirer d’une convention existante pour bâtir la sienne, il est important de le faire en adaptant la liste des types aux besoins du projet et en veillant à ce que chacun s’accorde sur le sens de chaque type. On peut s’en assurer, par exemple, en documentant ces choix dans le fichier CONTRIBUTING.md d’un projet.
Mes types
Cette précision apportée, on comprendra que la liste qui suit n’est donc pas directement issue de la spécification elle-même ni d’une convention existante, et n’est pas à réutiliser telle quelle. Il s’agit plutôt de donner des exemples au sens que l’on peut mettre derrière chaque type et d’inspirer des questions à se poser lors de l’établissement d’une convention.
fix
Un commit de type fix corrige un composant qui était censé fonctionner mais qui n’avait pas le comportement attendu. Si le bug a été introduit dans la PR (pull request) en cours, alors il n’est pas pertinent de dédier un commit au correctif. Mieux vaut amender le commit qui a introduit le bug. De plus, si le bug a échappé à l’attention des devs, c’est sans doute qu’il manque un test. Ce commit devrait donc ajouter un nouveau test ou corriger un test existant pour éviter toute régression.
feat
Un commit de type feat introduit une nouvelle fonctionnalité ou modifie une fonctionnalité existante. Il permet à l’utilisateur de faire quelque chose qu’il n'était pas possible de faire avant ou de le faire autrement. Ce commit devrait être accompagné des tests qui permettent de valider le bon fonctionnement du composant qui supporte la fonctionnalité.
refactor
Un commit de type refactor introduit un changement qui vise à améliorer le code en le rendant, par exemple, plus facilement compréhensible ou maintenable. Ce changement devrait être absolument transparent pour l’utilisateur et ne jamais modifier l’interface publique d’une application (par exemple, les routes d’une API ou les aspects visuels d’une application front-end). En conséquence, parce qu’il ne peut affecter que des composants internes et leur manière de fonctionner entre eux, il ne devrait jamais modifier un test d’acceptance ou end-to-end mais peut modifier des tests unitaires.
perf
Le type perf est un type particulier de refactor qui vise à améliorer les performances d’un composant, dont on estime qu’il fonctionnait correctement (ce n’est pas un fix), sans modifier son interface publique (ce n'est pas un feat). Contrairement à refactor, un commit de type perf affecte bel et bien l’utilisateur (de manière positive). Parce que les performances d’un composant sont difficiles à tester de manière automatisée, il est probable que ce commit ne concerne pas les tests.
test
Un commit de type test n’affecte que les tests, pour ajouter un test manquant, corriger un test flaky4 ou améliorer les performances d’un test. Si d’autres fichiers de code sont affectés par ce commit, c’est peut-être le signe que l’implémentation dépend des tests (ce qui est une mauvaise pratique).
style
Un commit de type style introduit un changement qui n’affecte pas l’exécution du code, mais uniquement son style : indentation, retour à la ligne, espacement, virgule en fin de liste, point-virgules en fin de ligne, etc. Bien souvent, ces changements sont introduits ou rendus nécessaires par les linters de code. Attention : on ne parle pas ici de style au sens CSS ! 5
docs
Un commit de type docs n’affecte que la documentation. Celle-ci se trouve en général dans des répertoires dédiés et dans des fichiers de type text ou markdown, mais aussi parfois dans le code si le commit concerne des commentaires (qui sont une forme de documentation).
build
Un commit de type build concerne uniquement les fichiers liés au système de build : package.json, (par exemple, ajoute d’une dépendance ou changement de version de node), fichiers de configuration des outils de compilation/transpilation, etc.
ci
Un commit de type ci n’affecte que les fichiers liés à la configuration des outils d’intégration continue soit, par exemple, Github Action ou Circle CI, qui se trouvent dans des répertoires dédiés.
Choisir le bon type
Quand on ne connaît pas bien les différents types, il peut être difficile de choisir le bon. Créer un arbre de décision peut aider à se poser les bonnes questions. À titre d’exemple, voici un arbre de décision qui s’applique aux types proposés ci-dessus.
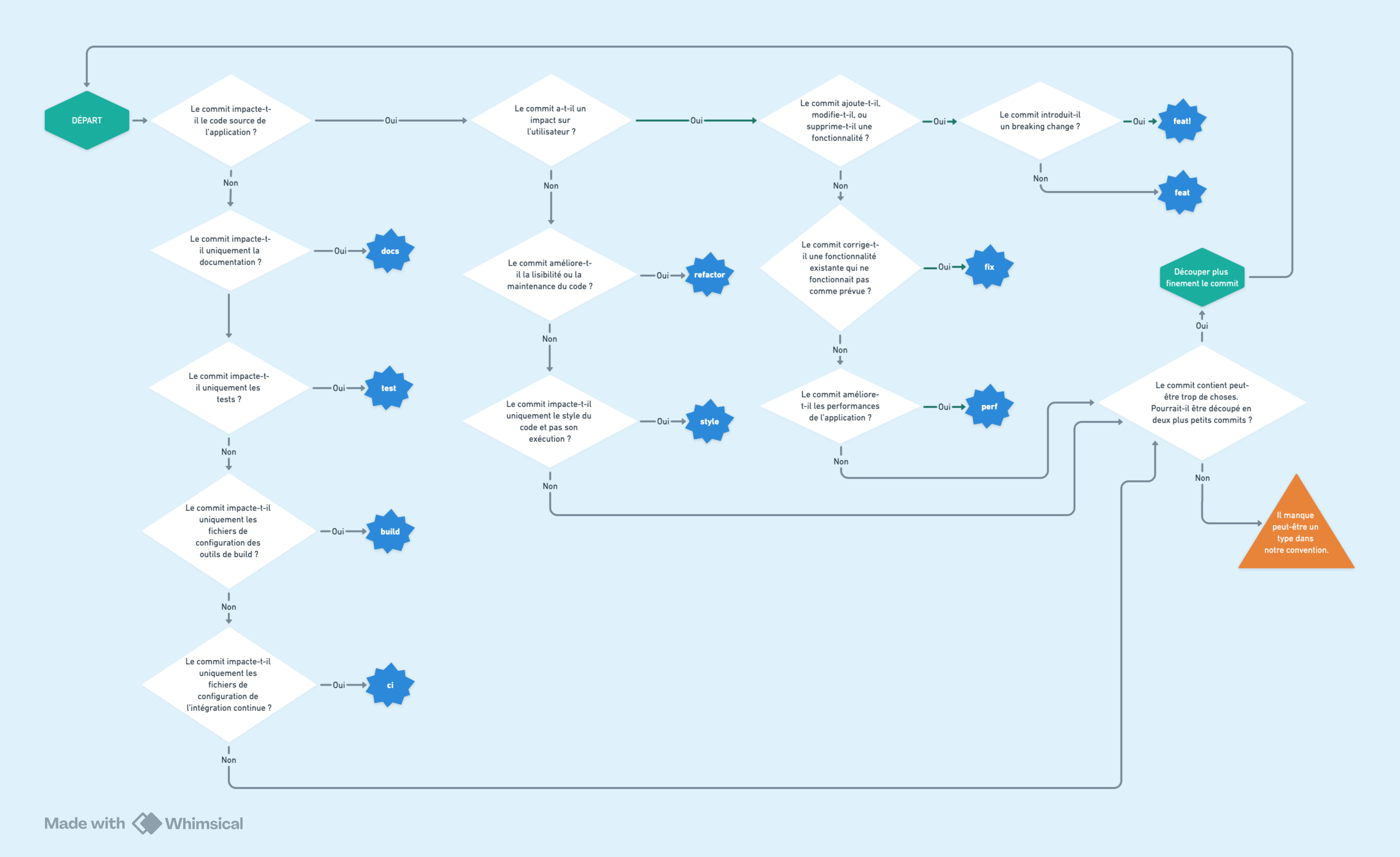
Version texte de l'arbre de décision
Si le commit impacte le code source de l’application
Si le commit a un impact sur l'utilisateur ou l'utilisatrice
Si le commit ajoute, modifie ou supprime une fonctionnalité
Si le commit introduit un breaking change
Alors le type estfeat!
Si le commit n'introduit pas de breaking change
Alors le type estfeat
Si le commit corrige une fonctionnalité existante qui ne se comportait pas comme prévu
Alors le type estfix
Si le commit améliore les performances de l'application
Alors le type estperf
Sinon
Si le commit pourrait être découpé plus finement
Découper le commit en plusieurs commits et revenir au point de départ pour chacunSinon
Il manque peut-être un type dans notre conventionSi le commit n'a pas d'impact sur l'utilisateur ou l'utilisatrice
Si le commit améliore la lisibilité ou facilite la maintenance du code
Alors le type estrefacto
Si le commit impacte uniquement le style du code et pas son exécution
Alors le type eststyle
Sinon
Si le commit pourrait être découpé plus finement
Découper le commit en plusieurs commits et revenir au point de départ pour chacunSinon
Il manque peut-être un type dans notre conventionSi le commit n'impacte pas le code source de l'application
Si le commit impacte uniquement la documentation
Alors le type estdocs.
Si le commit impacte uniquement les tests
Alors le type esttest.
Si le commit impacte uniquement les outils de compilation et leur configuration
Alors le type estbuild.
Si le commit impacte uniquement les outils d'intégration continue et leur configuration
Alors le type estci.
Sinon
Si le commit pourrait être découpé plus finement
Découper le commit en plusieurs commits et revenir au point de départ pour chacunSinon
Il manque peut-être un type dans notre conventionIl permet de faire apparaître trois grandes familles de types :
- Les commits qui affectent l’utilisateur :
feat,fix,perf; - Les commits qui affectent le code source, mais pas l’utilisateur :
refactor,style; - Les commits qui n’affectent pas le code source :
docs,test,build,ci.
Enfin, si aucun type ne semble correspondre, cela peut signifier deux choses :
- Le commit contient trop de code et il pourrait être découpé en plus petits commits dont chacun correspondrait à un type ;
- Il manque un type dans ceux proposés et il faut amender notre convention.
Seul on va plus vite, ensemble on va plus loin
Parfois, en travaillant sur une nouvelle fonctionnalité, on peut être tenté, au passage, de faire une refacto pour rendre un code plus lisible, de corriger une coquille dans le titre d’un test, de déplacer un bout de code dans une méthode pour le rendre réutilisable…
Et puis, certains de ces changements étant plus exploratoires, on va les abandonner en cours de route et on aura du mal à revenir à un état stable, sans opérations délicates. Peut-être pire, on ajoutera tout dans le même commit introduisant la nouvelle fonctionnalité, le rendant difficilement compréhensible pour la personne qui relira la pull request.
Si j’aime tant travailler avec des conventions telles que celles que peuvent nous aider à bâtir Conventional Commits, c’est parce qu’en nous obligeant à nous mettre à la place de l’autre, elles nous forcent réfléchir à la manière de raconter une histoire et à organiser notre travail en petites séquences logiques, qui deviendront au final des commits atomiques. En nous incitant à nous interroger sur le pourquoi plutôt que sur le quoi, elles nous invitent à sortir de la routine, à prendre un instant de recul pour réfléchir sur la raison et le sens de ce que l’on est en train de faire — quelque chose que l’on devrait faire plus souvent, dans le code comme dans la vie.
Ressources
- La spécification Conventional Commits.
- La convention Angular pour les commits.
- Commitlint, un outil pour valider les messages de commits.
À lire aussi
- Sur l’utilisation de Conventional Commits pour l’automatisation : The Power of Conventional Commits.
- Sur ce qui fait un bon commit, au-delà de son message : Qu'est-ce qu'un bon message de commit ?)
Merci à Yann Bertrand, Jules Alexiu et Anne Kozlika pour leur relecture.
-
Un dépôt git abritant plusieurs projets, souvent chacun dans un dossier différent à la racine. ↩
-
Domain-driven design, ou en français Conception pilotée par le domaine, une approche qui consiste, notamment, à modéliser explicitement les différents domaines recouverts par une activité, lesquels peuvent servir de scope au sens Conventional Commits. ↩
-
Contrairement aux autres éléments facultatifs, dont la présence peut varier d’un commit à un autre, l'étendue devrait être facultative ou obligatoire à l’échelle du projet. Un petit projet peut tout à fait ne peut pas nécessiter d'étendue, par contre si, pour un projet plus important, une liste d'étendues a été définie, alors chaque commit devrait le préciser. ↩
-
Un test flaky (qu'on pourrait traduire par « fragile ») est un test qui ne donne pas le même résultat à chaque exécution et peut échouer sans pour autant que cela indique un problème dans l'implémentation testée. Voir la conférence L'instabilité de nos tests nous empêche de délivrer. ↩
-
On voit parfois le type
styleutilisé de manière erronée pour la modification d’un style CSS, or ce n’est pas son objet. On peut s’en souvenir en se disant qu’utiliserstylepour du CSS, ce serait parler du quoi alors que ce l’on veut, c’est expliciter le pourquoi (par exemple, parce que le style du code ne respectait pas un standard). ↩
Il n’est plus possible de laisser un commentaire sur les articles mais la discussion continue :